Understanding kubernetes networking: pods and services
In this series I will attempt to demystify the Kubernetes networkiing layers. This first part will look at containers and pods.
What is a pod?
A Pod is the atom of Kubernetes — the smallest deployable object for building applications. A single Pod represents an applications in your cluster and encapsulates one or more containers. Containers that make up a pod are designed to be co-located and scheduled on the same machine. They share the same resources like ip, network and volumes. In Linux, each running process communicates within a Linux namespace that provides a logical networking stack. In essence, a pod is a representation of a Linux namespace that allow the containers to usa the same resources. Containers within a Pod all have the same IP address and port range. They can find each other via localhost since they reside in the same namespace. This means the containers in a pod can not us the same ports.
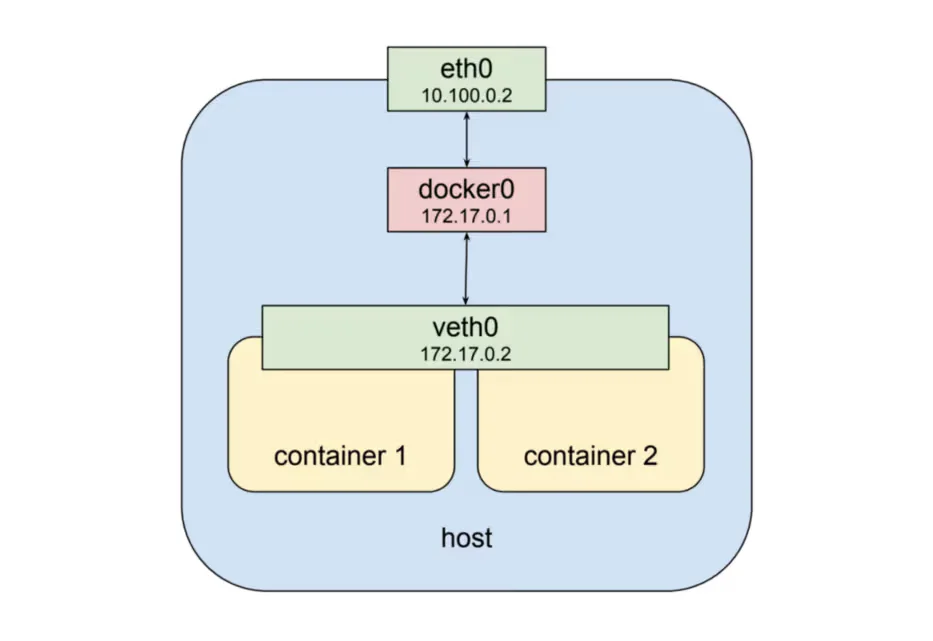
Kubernetes creates a special container for each pod whose purpose is to provide a network interface for the other containers. This is the “pause” container.
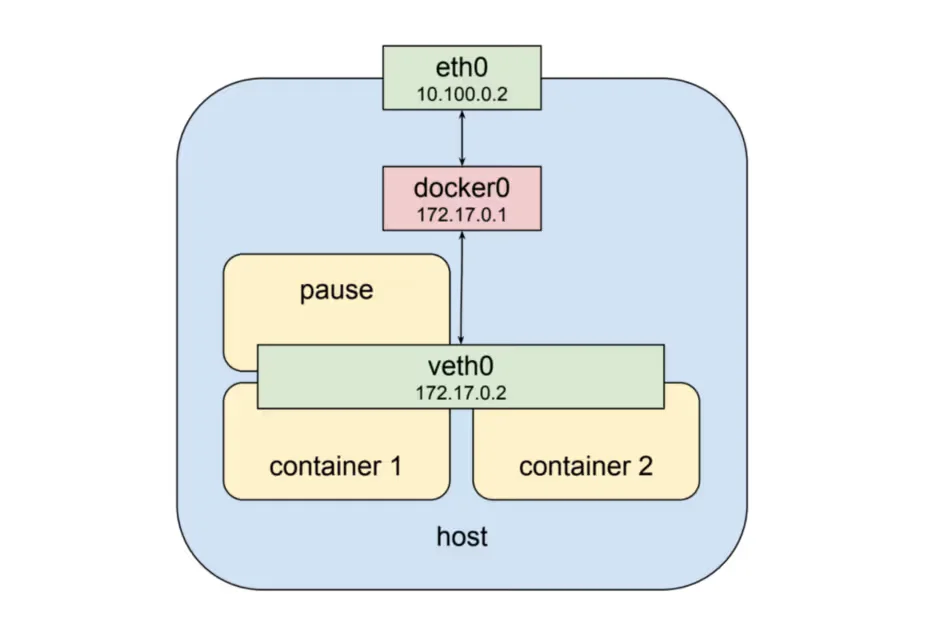
Pod-to-Pod communication
Every Pod has a real IP address and each Pod communicates with other Pods using that IP address. From the Pod’s perspective, it exists in its own Ethernet namespace that needs to communicate with other network namespaces on the same Node. Namespaces can be connected using a Linux Virtual Ethernet Device (veth) This setup can be replicated for as many Pods as we have on the machine. The default Gateway in this internal network is a Linux bridge. A bridge is a virtual Layer 2 networking device used to unite two or more network segments to connect networks together.
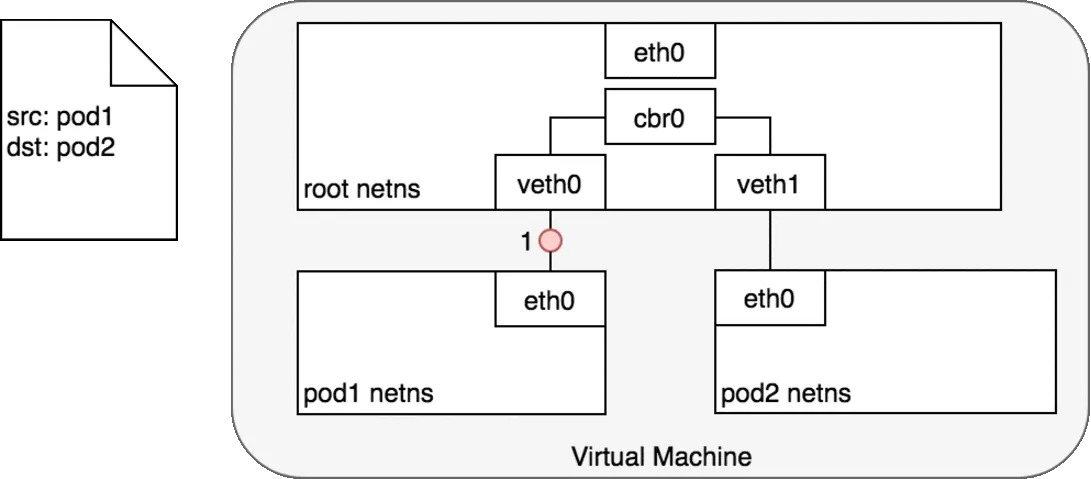
Bridges implement the ARP protocol to discover the link-layer MAC address associated with a given IP address.
What is a Service?
As we know containers are considered disposable. That means there is no guarantee that the pod’s address won’t change the next time the pod is recreated. That is a common problem in cloud environments too, and it has a standard solution: run the traffic through a reverse-proxy. This proxy is represented by a Kubernetes resource type called a service.
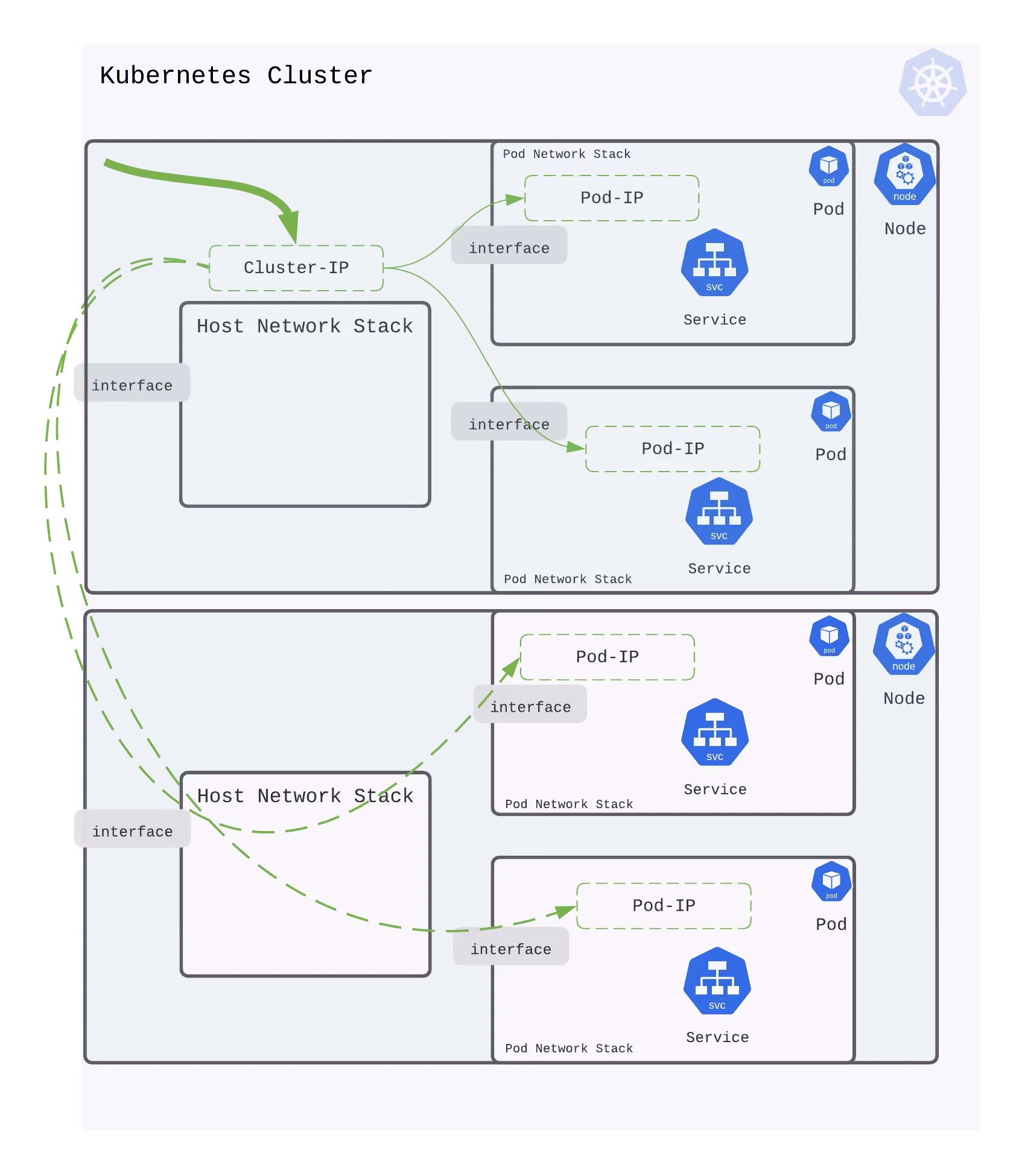
Service Types
ClusterIP
ClusterIP is the default and most common service type. Kubernetes will assign a cluster-internal IP address to ClusterIP service. This makes the service only reachable within the cluster. You can use it for inter service communication within the cluster. For example, communication between the front-end and back-end components of your app.
NodePort
NodePort service is an extension of ClusterIP service. It exposes the service outside of the cluster by adding a cluster-wide port nat on top of ClusterIP. Each node proxies that port to there ip. So, external traffic has access to fixed port on each Node. ode port must be in the range of 30000–32767. Manually allocating a port to the service is optional. If it is undefined, Kubernetes will automatically assign one.
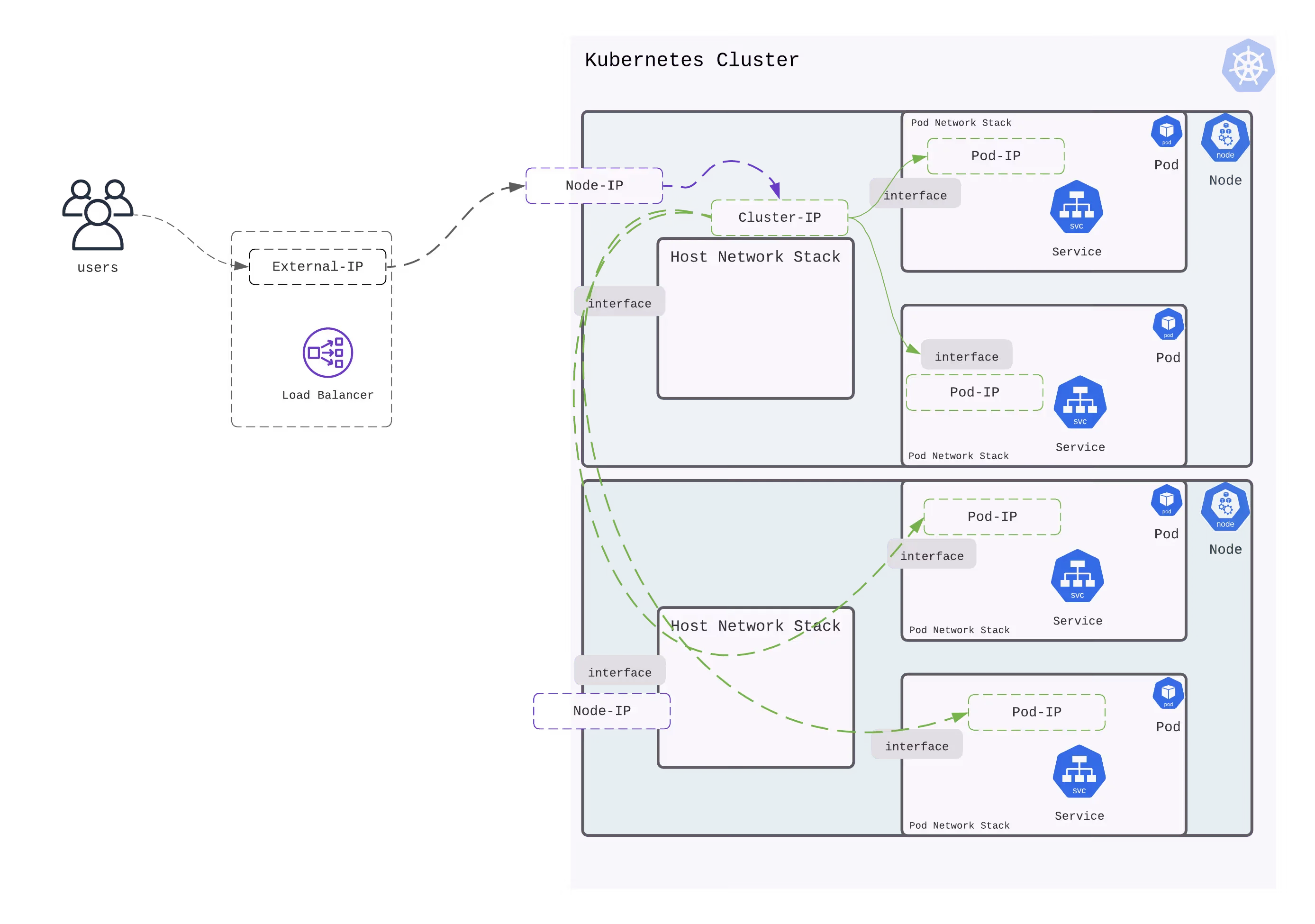
LoadBalancer
LoadBalancer service is an extension of NodePort service. It integrates NodePort with cloud-based load balancers. It exposes the Service externally using a cloud provider’s load balancer. Each cloud provider (AWS, Azure, GCP, etc) has its own native load balancer implementation. The cloud provider will create a load balancer, which then automatically routes requests to your Kubernetes Service. Traffic from the external load balancer is directed at the backend Pods. The cloud provider decides how it is load balanced. Every time you want to expose a service to the outside world, you have to create a new LoadBalancer and get an IP address.
ExternalName
ExternalName map a Service to a DNS name, not to a typical selector. It maps the Service to the contents of the externalName field (e.g. foo.bar.example.com), by returning a CNAME record with its value. This is commonly used to create a service within Kubernetes to represent an external datastore like a database that runs externally to Kubernetes.
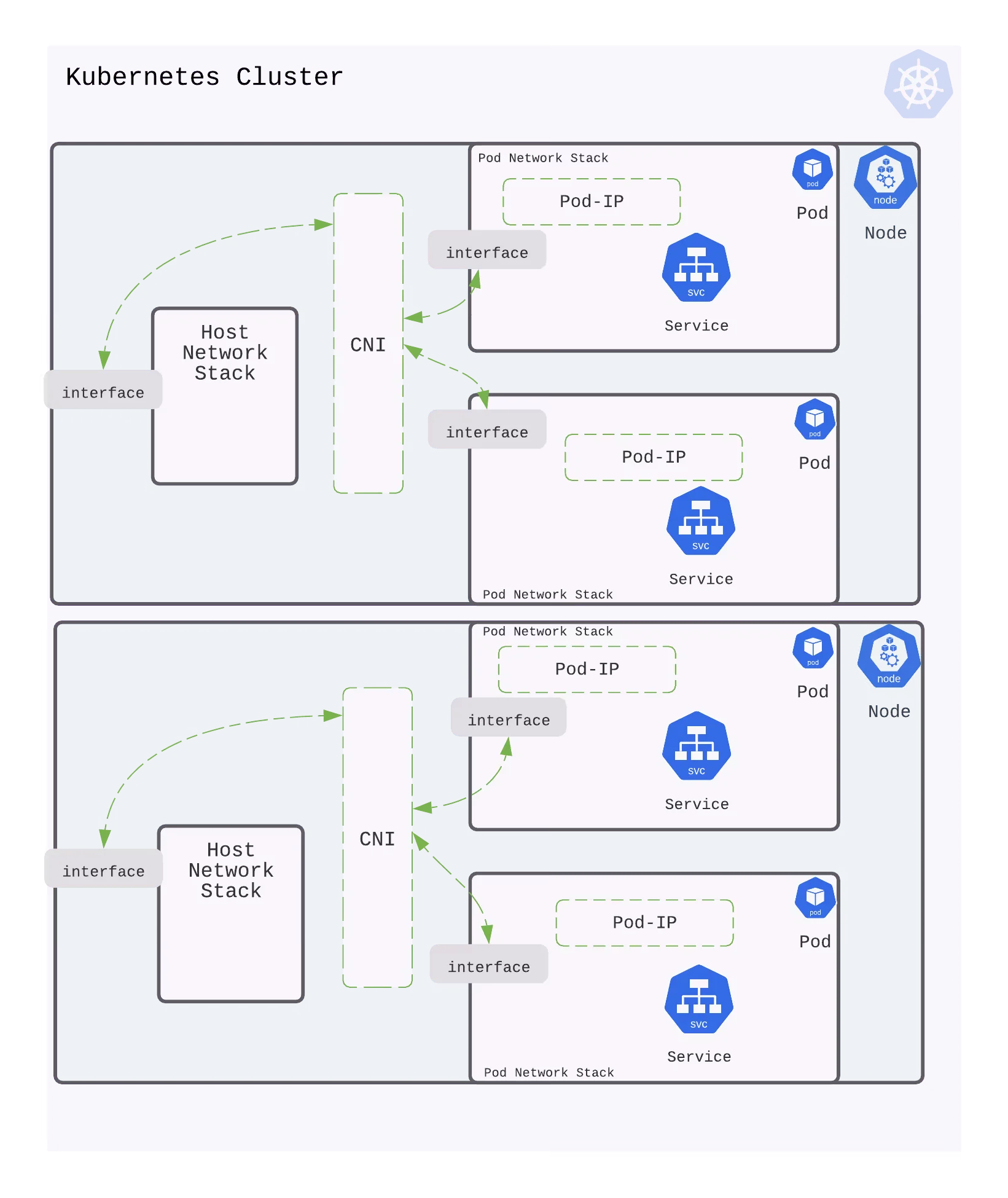
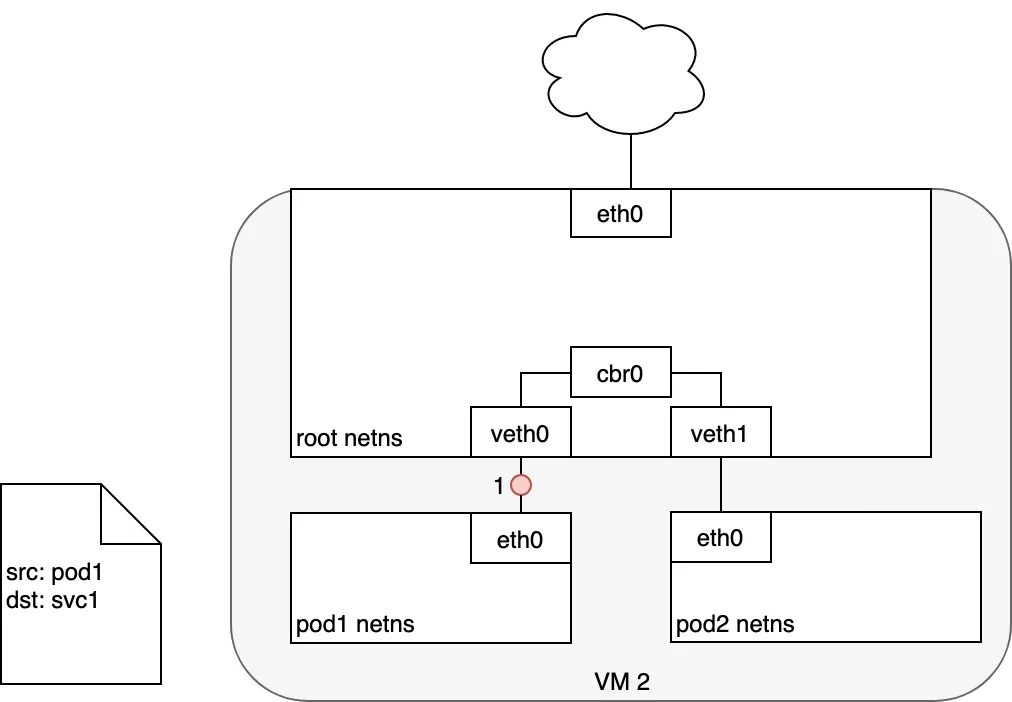
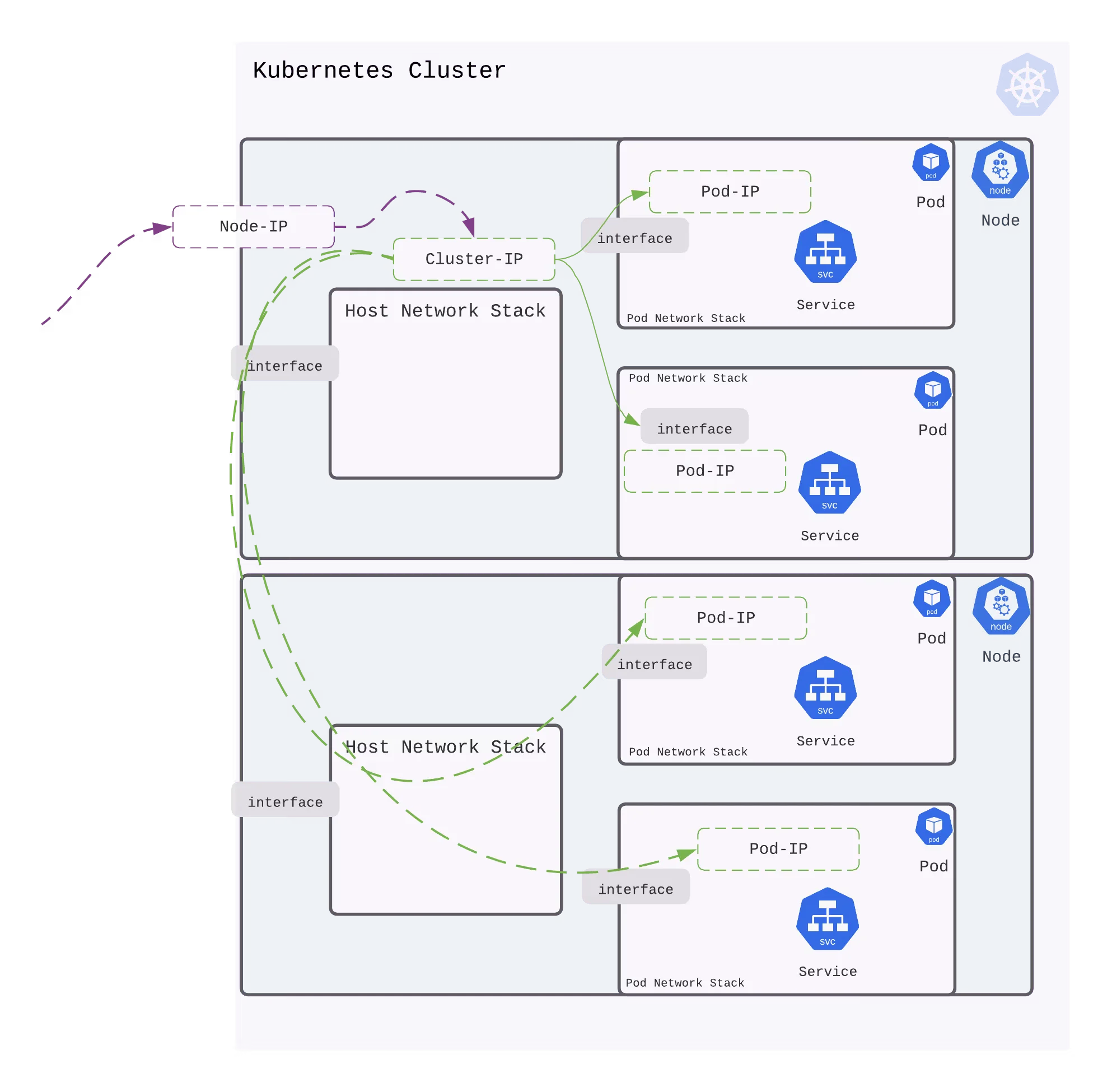
Pod-to-Service communication
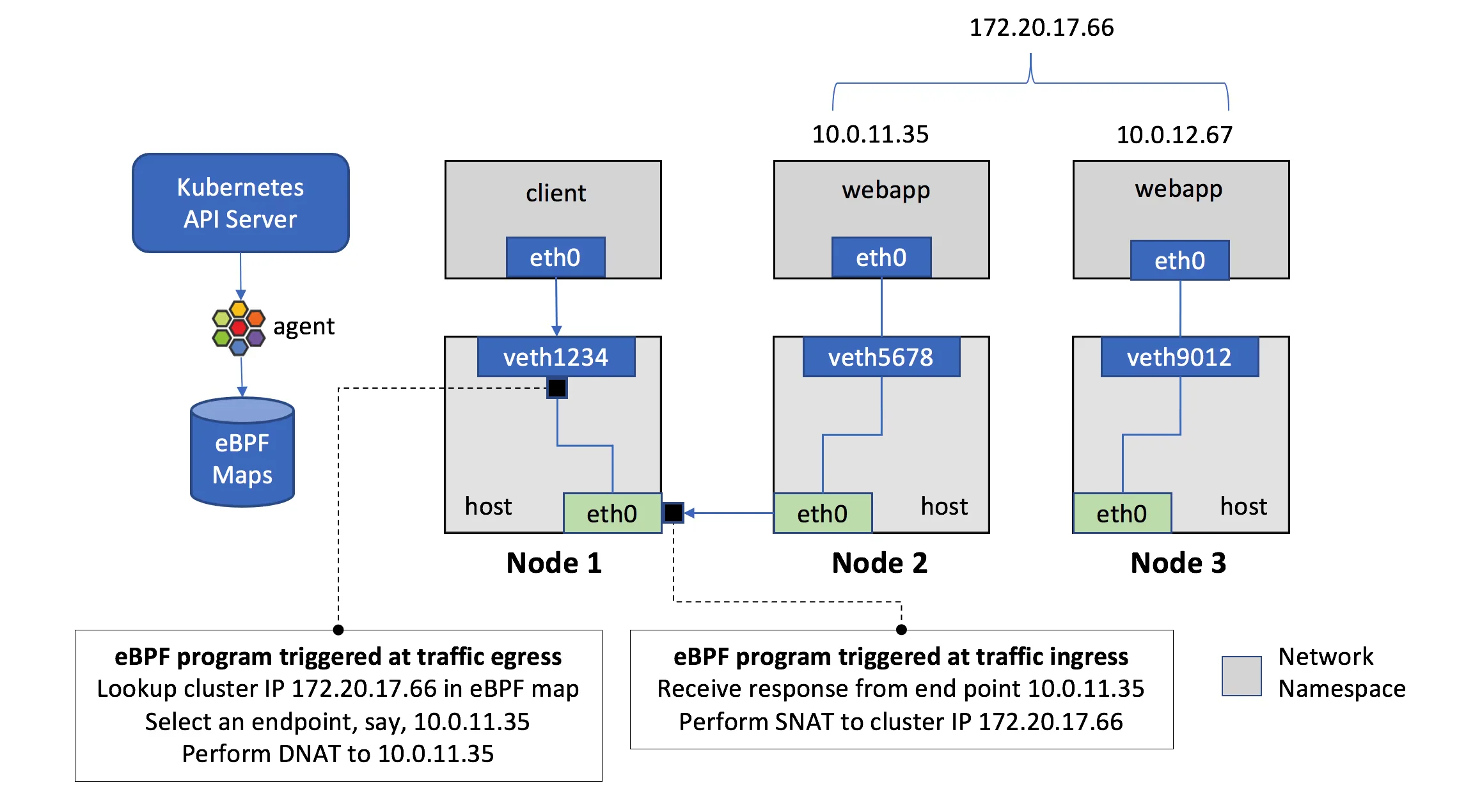
When creating a new Kubernetes Service, a new virtual IP is created on your behalf. Anywhere within the cluster, traffic addressed to this virtual IP will be routed or load-balanced to the Pod or Pods associated with the Service. Kubernetes use a networking framework built in to Linux kernel called netfilter.
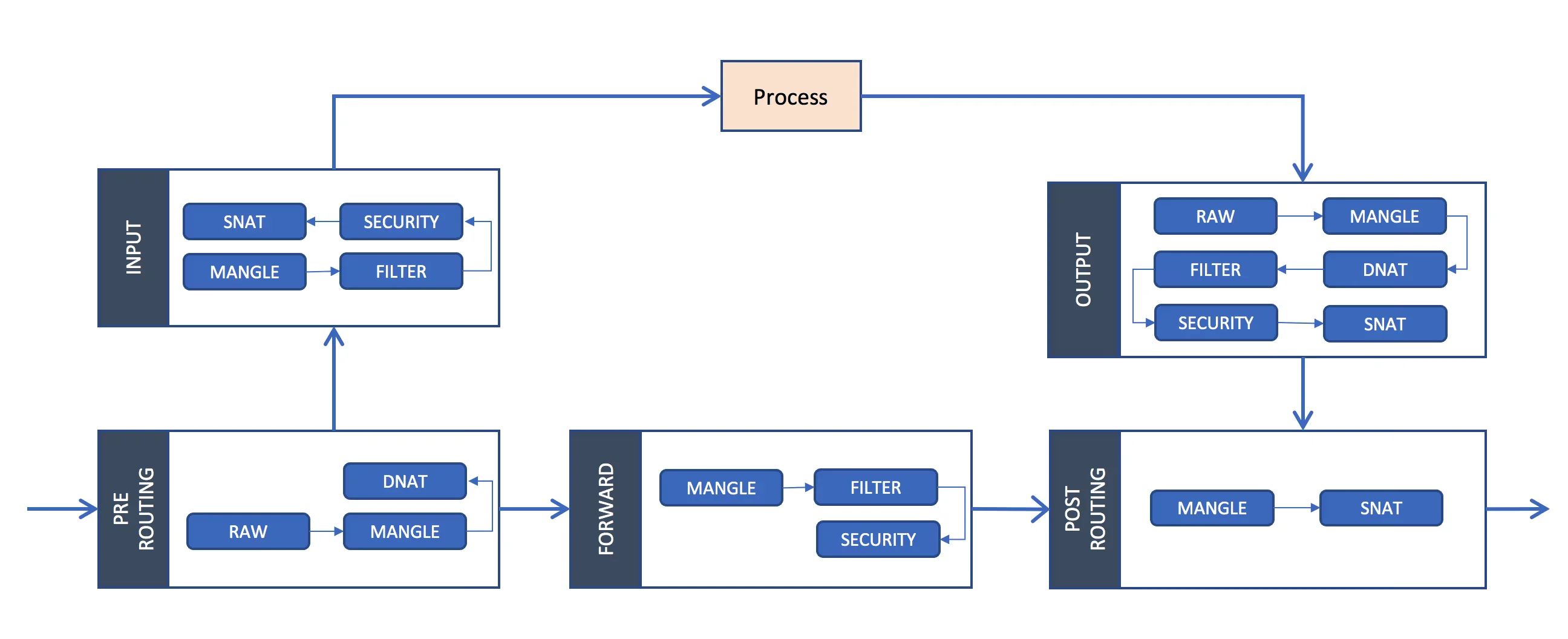
iptables is a user-space utility program that allows a system administrator to configure the IP packet filter rules of the Linux kernel firewall, implemented as different Netfilter modules. In Kubernetes, iptables rules are configured by the kube-proxy controller that watches the Kubernetes API for changes. Creation of a service or change of the pod ip will trigger iptables rules update on the host. When a traffic destined for a Service’s virtual IP is detected the kube-proxy select a random pod ip from the set of available Pods and manipulate the iptables rules to change the destination ip in the package to it. This method is called destination nat. In the return path iptables again rewrites the IP header to replace the Pod IP with the Service’s IP. The path taken by a packet through the networking stack is depicted in the figure shown below:

In the iptables perspective:
IPVS
Since verion 1.11 Kubernetes includes a second option for load balancing. IPVS (IP Virtual Server) is also built on top of netfilter and implements load balancing as part of the Linux kernel. IPVS can direct requests for TCP- and UDP-based services to the real servers, and make services of the real servers appear as virtual services on a single IP address. When creating a Service load balanced with IPVS, three things happen: a dummy IPVS interface is created on the Node, the Service’s IP address is bound to the dummy IPVS interface, and IPVS servers are created for each Service IP address.

eBPF
Some Network plugin is Kubernetes can act as a replacement for kube-proxy like Calico and Cilium. They use eBPF as a solution to solve the load-balancing problem.
What is eBPF?
eBPF is a virtual machine embedded within the Linux kernel. It allows small programs to be loaded into the kernel, and attached to hooks, which are triggered when some event occurs. This allows the behavior of the kernel to be (sometimes heavily) customized. While the eBPF virtual machine is the same for each type of hook, the capabilities of the hooks vary considerably. Since loading programs into the kernel could be dangerous; the kernel runs all programs through a very strict static verifier; the verifier sandboxes the program, ensuring it can only access allowed parts of memory and ensuring that it must terminate quickly.
eBPF dataplane attaches eBPF programs to hooks on each bridge interface as well as your data and tunnel interfaces. This allows Calico or Cilium to spot workload packets early and handle them through a fast-path that bypasses iptables and other packet processing that the kernel would normally do.
Calico:

Cilium: