Kubernetes audit logs and Falco

In this blog post I will show you how how you can use Kubernetes the audit logs and Falco for detecting suspicious activities in you cluster.
Parts of the K8S Security Lab series
Container Runetime Security
- Part1: How to deploy CRI-O with Firecracker?
- Part2: How to deploy CRI-O with gVisor?
- Part3: How to deploy containerd with Firecracker?
- Part4: How to deploy containerd with gVisor?
- Part5: How to deploy containerd with kata containers?
Advanced Kernel Security
- Part1: Hardening Kubernetes with seccomp
- Part2: Linux user namespace management wit CRI-O in Kubernetes
- Part3: Hardening Kubernetes with seccomp
Network Security
- Part1: RKE2 Install With Calico
- Part2: RKE2 Install With Cilium
- Part3: CNI-Genie: network separation with multiple CNI
- Part3: Configurre network wit nmstate operator
- Part3: Kubernetes Network Policy
- Part4: Kubernetes with external Ingress Controller with vxlan
- Part4: Kubernetes with external Ingress Controller with bgp
- Part4: Central authentication with oauth2-proxy
- Part5: Secure your applications with Pomerium Ingress Controller
- Part6: CrowdSec Intrusion Detection System (IDS) for Kubernetes
- Part7: Kubernetes audit logs and Falco
Secure Kubernetes Install
- Part1: Best Practices to keeping Kubernetes Clusters Secure
- Part2: Kubernetes Secure Install
- Part3: Kubernetes Hardening Guide with CIS 1.6 Benchmark
- Part4: Kubernetes Certificate Rotation
User Security
- Part1: How to create kubeconfig?
- Part2: How to create Users in Kubernetes the right way?
- Part3: Kubernetes Single Sign-on with Pinniped OpenID Connect
- Part4: Kubectl authentication with Kuberos Depricated !!
- Part5: Kubernetes authentication with Keycloak and gangway Depricated !!
- Part6: kube-openid-connect 1.0 Depricated !!
Image Security
Pod Security
- Part1: Using Admission Controllers
- Part2: RKE2 Pod Security Policy
- Part3: Kubernetes Pod Security Admission
- Part4: Kubernetes: How to migrate Pod Security Policy to Pod Security Admission?
- Part5: Pod Security Standards using Kyverno
- Part6: Kubernetes Cluster Policy with Kyverno
Secret Security
- Part1: Kubernetes and Vault integration
- Part2: Kubernetes External Vault integration
- Part3: ArgoCD and kubeseal to encript secrets
- Part4: Flux2 and kubeseal to encrypt secrets
- Part5: Flux2 and Mozilla SOPS to encrypt secrets
Monitoring and Observability
- Part6: K8S Logging And Monitoring
- Part7: Install Grafana Loki with Helm3
Backup
In the previous post I configured CISA’s best practices for the Kubernetes cluster. One of this best practice is to enable Kubernetes audit logging. It’s a key feature in securing your Kubernetes cluster, as the audit logs capture events like creating a new deployment, deleting namespaces, starting a node port service, etc.
When a request, for example, creates a pod, it’s sent to the kube-apiserver. You can configure kube-apiserver to write all of this activities to a log file. Each request can be recorded with an associated stage. The defined stages are:
- RequestReceived: The event is generated as soon as the request is received by the audit handler without processing it.
- ResponseStarted: Once the response headers are sent, but before the response body is sent. This stage is only generated for long-running requests (e.g., watch).
- ResponseComplete: The event is generated when a response body is sent.
- Panic: Event is generated when panic occurs.
Enable Kubernetes audit policy
You can enable this in the kubeadm conif as I did it in the previous post or edit the manifest of the running api server on the masters:
nano /etc/kubernetes/manifests/kube-apiserver.yaml
spec:
containers:
- command:
- kube-apiserver
...
- --audit-log-path=/var/log/kube-audit/audit.log
- --audit-policy-file=/etc/kubernetes/audit-policy.yaml
...
With security in mind, we’ll create a policy that filters requests related to pods, kube-proxy, secrets, configurations, and other key components. Such a policy would look like:
mkdir /var/log/kube-audit
nano /etc/kubernetes/audit-policy.yaml
---
apiVersion: audit.k8s.io/v1 # This is required.
kind: Policy
# Don't generate audit events for all requests in RequestReceived stage.
omitStages:
- "RequestReceived"
rules:
# Log pod changes at RequestResponse level
- level: RequestResponse
resources:
- group: ""
# Resource "pods" doesn't match requests to any subresource of pods,
# which is consistent with the RBAC policy.
resources: ["pods"]
# Log "pods/log", "pods/status" at Metadata level
- level: Metadata
resources:
- group: ""
resources: ["pods/log", "pods/status"]
# Don't log requests to a configmap called "controller-leader"
- level: None
resources:
- group: ""
resources: ["configmaps"]
resourceNames: ["controller-leader"]
# Don't log watch requests by the "system:kube-proxy" on endpoints or services
- level: None
users: ["system:kube-proxy"]
verbs: ["watch"]
resources:
- group: "" # core API group
resources: ["endpoints", "services"]
# Don't log authenticated requests to certain non-resource URL paths.
- level: None
userGroups: ["system:authenticated"]
nonResourceURLs:
- "/api*" # Wildcard matching.
- "/version"
# Log the request body of configmap changes in kube-system.
- level: Request
resources:
- group: "" # core API group
resources: ["configmaps"]
# This rule only applies to resources in the "kube-system" namespace.
# The empty string "" can be used to select non-namespaced resources.
namespaces: ["kube-system"]
# Log configmap and secret changes in all other namespaces at the Metadata level.
#- level: Metadata
- level: Request
resources:
- group: "" # core API group
resources: ["secrets", "configmaps"]
# Log all other resources in core and extensions at the Request level.
- level: Request
resources:
- group: "" # core API group
- group: "extensions" # Version of group should NOT be included.
# A catch-all rule to log all other requests at the Metadata level.
- level: Metadata
# Long-running requests like watches that fall under this rule will not
# generate an audit event in RequestReceived.
omitStages:
- "RequestReceived"
Then restart the api server:
systemctl restart kubelet
What is Falco?
OK we hawe a log file at /var/log/kube-audit/audit.log, but what can we do with it? We need a tool to monitor and alert based on the events in the audit log. This tool is Falco. Falco makes it possible to monitor suspicious events directly inside the cluster. The events may include the following:
- Outgoing connections to specific IPs or domains
- Use or mutation of sensitive files such as /etc/passwd
- Execution of system binaries such as su
- Privilege escalation or changes to the namespace
- Modifications in certain folders such as /sbin
Falco architecture
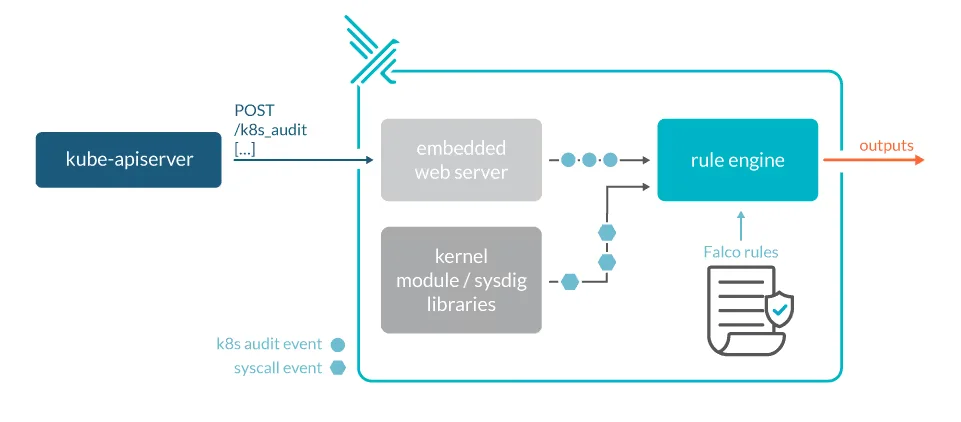
From a high-level view, Falco is comprised of the following components:
- Event sources (drivers, Kubernetes audit events)
- A rule engine and a rule set
- An output system integration
Falco uses so-called drivers to monitor syscalls made by applications at the kernel level; it can therefore monitor everything that results in a syscall. As containers share a kernel, it is possible to monitor syscalls by all the containers on a host. This is not possible in the case of more isolated container engines like Kata Containers or Firecracker. Falco supports two types of drivers: kernel module, eBPF probe:
- Kernel module (the default): A kernel module that must be compiled for the kernel that Falco will run on.
- eBPF probe: No need to load a kernel module, but requires a newer kernel that supports eBPF. Not supported on many managed services.
Install falco
First we need to install the devel kernel headers to allow falco to build the kernel mosul that Falco use to get syscalls.
apt-get -y install linux-headers-$(uname -r)
# or
yum -y install kernel-devel-$(uname -r)
We can install falco client az a package:
curl -s https://falco.org/repo/falcosecurity-3672BA8F.asc | apt-key add -
echo "deb https://download.falco.org/packages/deb stable main" | tee -a /etc/apt/sources.list.d/falcosecurity.list
apt-get update -y
apt-get install -y falco
# or
rpm --import https://falco.org/repo/falcosecurity-3672BA8F.asc
curl -s -o /etc/yum.repos.d/falcosecurity.repo https://falco.org/repo/falcosecurity-rpm.repo
yum -y install falco
falco-driver-loader
service falco start
journalctl -fu falco
Or install as docker container:
helm repo add falcosecurity https://falcosecurity.github.io/charts
helm repo update
helm upgrade --install falco falcosecurity/falco --namespace falco \
--set falcosidekick.enabled=true \
--set falcosidekick.webui.enabled=true \
--set auditLog.enabled=true
helm ls
kubectl get pods --namespace falco
NAME READY STATUS RESTARTS AGE
falco-falcosidekick-76f5885f7f-956vj 1/1 Running 0 4m27s
falco-falcosidekick-76f5885f7f-tmff6 1/1 Running 0 4m27s
falco-falcosidekick-ui-5b64749bc8-k8v4p 1/1 Running 0 4m27s
falco-h4qvx
I prefer this solution because it is more elegant. For the easier installation I created a helmfile:
cd /opt
git clone https://github.com/devopstales/k8s_sec_lab
cd k8s_sec_lab/k8s-manifest
kubectl apply -f 120-falco-ns.yaml
kubectl apply -f 122-falco.yaml
Processing Falco logs with a logging system
Falco provides support for a variety of output channels for generated alerts. These can include stdout, gRPC, syslog, a file, and more. In my exaple I used loki and alertmanager.
cat 122-falco.yaml
...
spec:
chart: falco
repo: "https://falcosecurity.github.io/charts"
targetNamespace: falco-system
valuesContent: |-
...
config:
loki:
hostport: http://logging-loki.logging-system:3100
customfields: "source:falco"
alertmanager:
hostport: http://monitoring-kube-prometheus-alertmanager.monitoring-system:9093
minimumpriority: error
mutualtls: false
checkcert: false
Gathering Audit Logs by using FluentBit
In order to deploy FluentBit, I created a helmfile:
kubectl apply -f 123-falco-fluentbit.yaml
I use FluentBit to send the Kubernetes Kubernetes audit logs to falco.
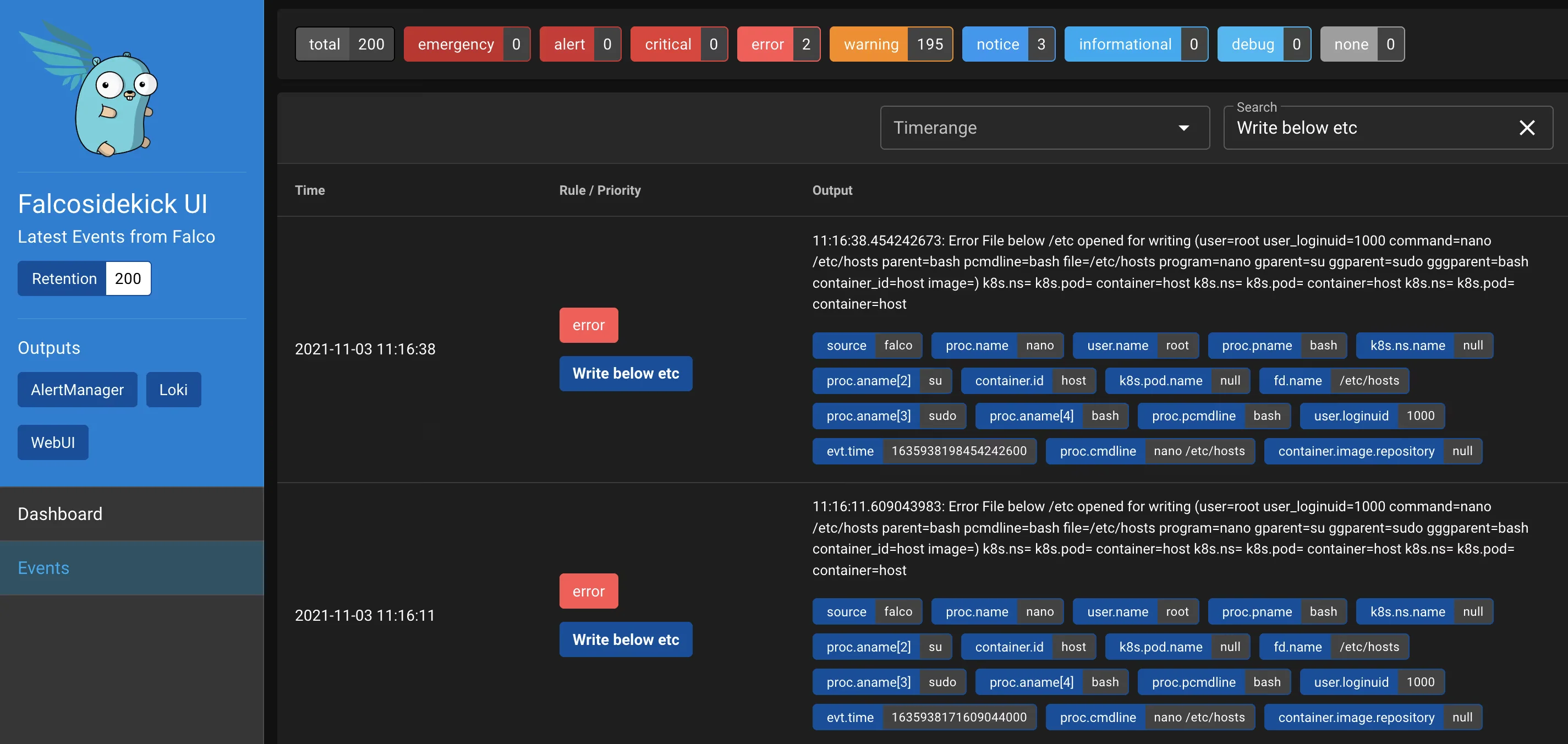
Test
kubectl --namespace=falco-system port-forward svc/falco-falcosidekick-ui 2802
Forwarding from 127.0.0.1:2802 -> 2802
Forwarding from [::1]:2802 -> 2802
On the master node edit the /etc/hosts file:
nano /etc/hosts
...
# test